I recently had a customer who had built a 2-node Availability Group & FSW in AWS. The customer chose to manually build the AG, vs. using the pre-configured AWS quickstart template. The build went as expected, however the customer could not successfully reach the listener, nor fail-over properly. I have used the quickstart template every time I have built AG’s in AWS, so I recommended this to the customer. Having already invested a bunch of time in to this build, they wanted to see if we could fix what was already deployed.
After a quick screen share, everything seemed to be in order on the nodes themselves from a high level. Different subnets as required on AWS, proper configuration, and none of the common mistakes I see with AGs.
Knowing there’s a special requirement in Azure to handle the floating VIPs with an internal load balancer, I then set out to check Google to see what was missed.
Most of the documentation I found on Amazon’s site seemed to just reference the quickstart template, and really didn’t give any more detailed requirements or configuration detail. After a few more minutes, I came across a “Windows Wednesday” article from 2013 entitled “Windows Wednesday – AWS Implementation Guide for Microsoft SQL Server 2012 AlwaysOn Availability Groups” that seemed pretty relevant. While the linked PDF by David Pae and Ulf Schoo was geared toward building an SQL Server 2012 AG, the general process hasn’t changed all that much, so I gave it a read.
It, too, covered using a quickstart template, but it appeared to be an older version, as there were less parameters mentioned, and the guide showed a bit more manual configuration.
And then there it was, on page 11. The missing link.
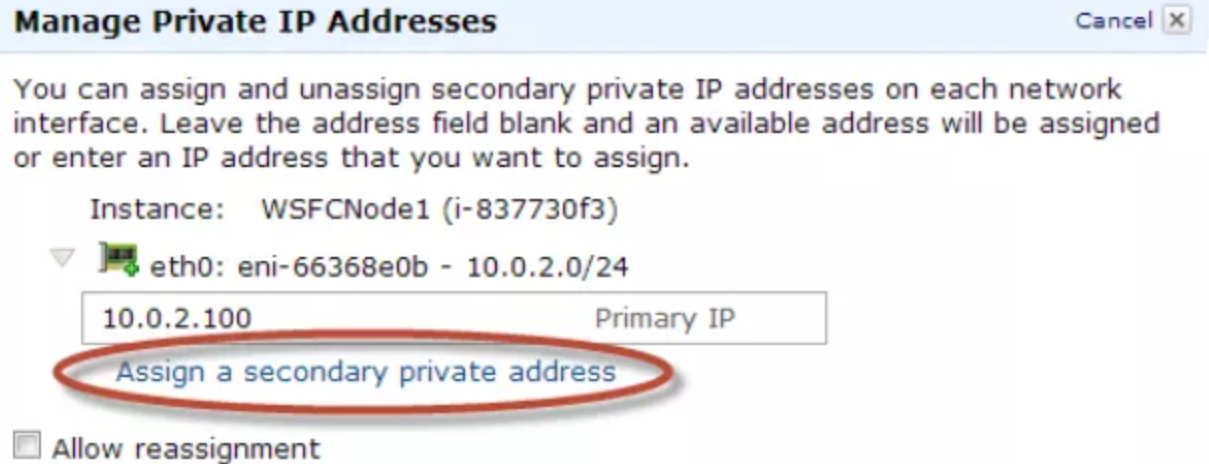
On an AWS implementation, VIPs must be added as “secondary private addresses” to each node, in the AWS console itself, and not just through the operating system

by David Pae, Ulf Schoo

This image is from page 11 of the PDF “Implementing Microsoft Windows Server Failover Clustering (WSFC) and SQL Server 2012 AlwaysOn Availability Groups in the AWS Cloud”
by David Pae, Ulf Schoo
The key is to add the IPs for both the WSFC management point, and the AG listener IP, to the correct node, based on subnet.
For example, we did something like this:
Node 1 (10.0.1.0 subnet)
10.0.1.10 – Node IP – Primary IP, already there
10.0.1.100 – WFSC IP – Added as secondary IP
10.0.1.150 – AG listener – Added as secondary IP
Node 2 (10.0.2.0 subnet)
10.0.2.10 – Node IP – Primary IP, already there
10.0.2.100 – WSFC IP – Added as secondary IP
10.0.2.150 – AG listener – Added as secondary IP
After a bit of discussion, we added all the secondary IPs to the nodes through the AWS console, and then rebooted each node for good measure. Once they came back up, everything was working correctly, and the issue was resolved. Total call time was a shade under 20 minutes to get to this point.
To quote Gavin Rossdale from the band Bush “It’s the little things that kill”
